2024. 6. 14. 15:05ㆍ김영한 Java/컬렉션 프레임워크
3. TreeSet
- 구현 : TreeSet은 이진 탐색 트리를 개선한 레드 - 블랙 트리를 내부에서 사용한다.
- 순서 : 요소들은 정렬된 순서로 저장된다. 순서의 기준은 비교자(Comparator)로 변경할 수 있다. 비교자는 뒤에서 다룬다.
- 시간 복잡도 : 주요 연산들은 O(log n)의 시간 복잡도를 가진다. 따라서 HashSet보다는 느리다.
- 용도 : 데이터들을 정렬된 순서로 유지하면서 집합의 특성을 유지해야 할 때 사용한다. 예를 들어, 범위 검색이나 정렬된 데이터가 필요한 경우에 유용하다. 참고로 입력된 순서가 아니라 데이터의 값의 순서이다. 예를 들어 3,1,2 를 순서대로 입력해도 1,2,3 순서로 출력된다.
트리 구조
TreeSet을 이해하려면 트리 구조를 먼저 알아야 한다.

- 트리는 부모 노드와 자식 노드로 구성된다.
- 가장 높은 조상을 루트(root)라 한다. 이 그림을 뒤집어 보면 왜 트리라고 하는지, 처음을 루트라고 하는지 이해가 될 것이다.
- 자식이 2개까지 올 수 있는 트리를 이진 트리라 한다.
- 여기에 노드의 왼쪽 자손은 더 작은 값을 가지고, 오른쪽 자손은 더 큰값을 가지는 것을 이진 탐색 트리라 한다.
- TreeSet은 이진 탐색 트리를 개선한 레드-블랙 트리를 사용한다. 기본 개념은 비슷하므로 이진 탐색 트리의 원리를 알아보자.
트리 구조의 구현

class Node{
Object item;
Node left;
Node right;
}- 트리 구조는 왼쪽, 오른쪽 노드를 알고 있으면 된다.
- 앞서 다룬 연결 리스트의 구현을 떠올려보면 쉽게 이해가 될 것이다.
이진 탐색 트리 - 입력 예시
이진 탐색 트리의 핵심은 데이터를 입력하는 시점에 정렬해서 보관한다는 점이다.
그리고 작은 값은 왼쪽에 큰 값은 오른쪽에 저장하면 된다.
데이터를 10,5,15,1,6,11,16 순서대로 입력한다고 가정해보자.
처음에 10을 입력했다고 가정하자. 다음으로 5, 15를 입력한다.
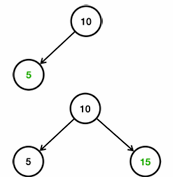
- 5는 10보다 작으므로 왼쪽에 저장된다.
- 15는 10보다 크므로 오른쪽에 저장된다.


- 1은 10보다 작다. 따라서 왼쪽으로 찾아간다. 1은 5보다 작다 따라서 왼쪽에 저장된다.
- 6은 10보다 작다. 따라서 왼쪽으로 찾아간다. 6은 5보다 크다. 따라서 오른쪽에 저장된다.
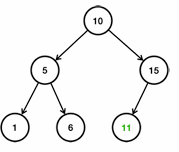
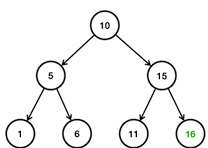
- 11은 10보다 크다 따라서 오른쪽으로 찾아간다. 11은 15보다 작다. 따라서 왼쪽에 저장된다.
- 16은 10보다 크다 따라서 오른쪽으로 찾아간다. 16은 15보다 크다. 따라서 오른쪽에 저장된다.
이진 탐색 트리 - 검색

- 여기에는 총 15개의 데이터가 들어있다. 여기서 숫자 35를 검색한다고 가정해보자.
- 1번 : 루트인 20과 35를 비교한다. 35가 더 크므로 오른쪽으로 찾아간다.
- 2번 : 40과 35를 비교한다. 35가 더 작으므로 왼쪽으로 찾아간다.
- 3번 : 30과 35를 비교한다. 35가 더 크므로 오른쪽으로 찾아가낟.
- 4번 : 노드에 있는 값을 비교한다. 35와 같으므로 35를 찾는다
데이터가 총 15개인데 4번의 계산으로 필요한 결과를 얻을 수 있었다. 이것은 O(n)인 리스트의 검색보다는 빠르고,O(1)인 해시의 검색 보다는 느리다.
- 리스트의 경우 O(n)이므로 15번의 연산이 필요하다.
- 해시 검색은 O(1)이므로 1번의 연산이 필요하다.
이진 탐색 트리 계산의 핵심은 한번에 절반을 날린다는 점이다. 계산을 단순화 하기 위해 15개의 데이터가 있다고 가정하자.

이진 탐색 트리의 빅오 - O(log n)

16개의 경우 단 4번의 비교 만으로 최종 노드에 도달할 수 있다. 이것을 정리하면 다음과 같다.

1024개의 데이터를 단 10번의 계산으로 원하는 결과를 찾을 수 있다. 데이터의 크기가 늘어나도 늘어난 만큼 한 번의 계싼에 절반을 날려버리기 때문에 O(n)과 비교해서 데이터의 크기가 클 수록 효과적이다.

이진 탐색 트리와 성능
이진 탐색 트리의 검색, 삽입, 삭제의 평균 성능은 O(log n)이다. 하지만 트리의 균형이 맞지 않으면 최악의 경우 O(n)의 성능이 나온다. 만약 데이터를 1,5,6,10,15 순서로 입력했다고 가정해보자
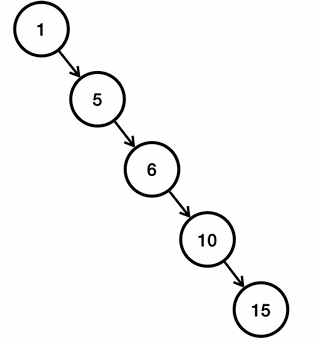
- 이렇게 오른쪽으로 치우치게 되면, 결과적으로 15를 검색 했을 때 데이터의 수인 5만큼 검색을 해야 한다.
- 따라서 이런 최악의 경우 O(n)의 성능이 나온다.
이진 탐색 트리 개선
이런 문제를 해결하기 위한 다양한 해결 방안이 있는데 트리의 균형이 너무 꺠진 경우 동적으로 균형을 다시 맞추는 것이다.
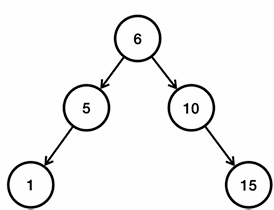
- 앞서 중간에 있는 6을 기준으로 다시 정렬한다.
- AVL트리, 레드-블랙 트리 같은 균형을 다시 맞추는 다양한 알고리즘이 존재한다.
- 자바의 TreeSet은 레드-블랙 트리를 사용해서 균형을 지속해서 유지한다. 따라서 최악의 경우에도 O(log n)의 성능을 제공한다.
이진 탐색 트리 - 순회
- 이진 탐색 트리의 핵심은 입력 순서가 아니라, 데이터의 값을 기준으로 정렬해서 보관한다는 점이다.
- 따라서 정렬된 순서로 데이터를 차례로 조회할 수 있다.(순회할 수 있다.)
- 데이터를 차례로 순회하려면 중위 순회라는 방법을 사용하면 된다. 왼쪽 서브트리를 방문한 다음, 현재 노드를 처리하고, 마지막으로 오른쪽 서브트리를 방문한다. 이 방식은 이진 탐색 트리의 특성상, 노드를 오름차순으로 방문한다.

중위 순회 순서
쉽게 이야기해서 자신의 왼쪽의 모든 노드를 처리하고, 자신의 노드를 처리하고, 자신의 오른쪽 모든 노드를 처리하는 방식이다.
- 10의 기준에서 왼쪽 서브트리를 방문한다.
- 5의 기준에서 왼쪽 서브트리를 방문한다
- 1을 출력한다.
- 5 자신을 출력한다.
- 5의 기준으로 오른쪽 서브트리를 방문한다.
- 6을 출력한다.
- 10 자신을 출력한다.
- 10의 기준에서 오른쪽 서브트리를 방문한다.
- 15의 기준에서 왼쪽 서브트리를 방문한다.
- 11을 출력한다.
- 15 자신을 출력한다
- 15의 기준으로 오른쪽 서브트리를 방문한다.
- 16을 출력한다.
- 15의 기준에서 왼쪽 서브트리를 방문한다.
- 5의 기준에서 왼쪽 서브트리를 방문한다
순서대로 1,5,6,10,11,15,16 출력된 것을 확인할 수 있다.
참고 : 여기서는 TreeSet을 알고 사용하기 위한 정도의 기본적인 트리 이론을 다루었다. 트리 구조에 대해서 더 자세히 알고 싶다면 자료구조와 알고리즘을 학습하자.
'김영한 Java > 컬렉션 프레임워크' 카테고리의 다른 글
| Map - 컬렉션 프레임워크 - Map 소개 1 (0) | 2024.06.17 |
|---|---|
| Set - 자바가 제공하는 Set4 - 최적화 (0) | 2024.06.14 |
| Set - 자바가 제공하는 Set1 - HashSet, LinkedHashSet (0) | 2024.06.14 |
| equals, hashCode의 중요성2 (0) | 2024.06.13 |
| equals, hashCode의 중요성 1 (0) | 2024.06.13 |